갑작스레 올라온 4.7, 그런데 이번엔 느낌이 달랐습니다
2026년 4월 16일, Claude Opus 4.7이 갑작스레 출시됐다고 합니다. 최근 Anthropic의 업데이트 주기가 워난 빨라서 버전 숫자가 올라가는 것 자체는 크게 놀라운 일이 아니었습니다. 2월에 4.6이 올라왔고, 그 사이에 Haiku 4.5 업데이트도 있었고, 1M 컨텍스트도 정식 기능으로 들어왔으니까요.
다만 이번 4.6에서 4.7로 넘어가는 변화는 체감이 달랐습니다. 숫자만 조금 오른 마이너 업데이트처럼 보이지만, 실제로 며칠 써보니 코딩 쪽에서 특히 놀라운 순간이 많았습니다. 동시에 "가격은 그대로"라는 공식 발표와 달리 실제 청구액은 올라간다고도 합니다. 토크나이저가 바뀌었기 때문입니다.
숫자가 올랐다고 체감이 같이 오르지는 않습니다. 그런데 4.6에서 4.7은 숫자도 오르고 체감도 같이 왔습니다. 대신 토큰값도 같이 올라왔습니다.
본격적으로 기능을 뜰어보기 전에, 4.6에서 쓰던 워크플로우와 4.7로 넘어가면서 달라진 지점을 한 장으로 먼저 정리해봤습니다. 같은 입력이 어떤 경로로 흘러가는지 나란히 두면, 체감과 비용이 왜 같이 움직이는지가 선명해집니다.
위쪽이 4.6 기준으로 돌리던 단순 흐름이고, 아래쪽이 4.7에서 바뀌 경로입니다. xhigh가 기본으로 들어오고, Task Budget과 자체 검증이 중간에 끼어들고, Claude Code 쪽에는 /ultrareview가 뒤에 붙는 구조입니다. 추론 깊이와 안정성이 같이 올라간 대신, 입력 토큰이 1.0에서 1.35배까지 늘어난다는 점이 같은 장면에 같이 담깁니다.
무엇이 바뀌었는지 먼저 한 줄씩 정리했습니다
가격은 입력 $5, 출력 $25 per 1M tokens로 동일하다고 합니다. 1M 컨텍스트와 128k 출력도 그대로이고, API 모델 ID는 claude-opus-4-7입니다. Claude.ai와 API는 물론 Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry에도 같은 날 배포됐습니다.
기능 쪽 핵심은 다섯 가지로 소개됐습니다.
- 비전 해상도 확대: 최대 2,576px(3.75MP)까지 처리한다고 합니다. 기술 다이어그램이나 UI 스크린샷의 작은 글씨도 잘 잡아낸다는 평가가 나오고 있습니다.
- xhigh effort level 추가: high와 max 사이의 새 추론 레벨이 생겼습니다. Claude Code는 이제 모든 플랜에서 xhigh가 기본값으로 들어갔다고 합니다.
- Task Budgets 베타: 에이전트 루프에 글로벌 토큰 예산을 걸어두면, 모델이 남은 예산을 보고 추론 깊이와 도구 호출 횟수를 스스로 조절해준다고 합니다.
- 자체 검증 강화: 자기 논리 오류를 스스로 포착하고, 데이터가 부족하면 억지로 답하지 않고 "부족하다"고 보고하는 경향이 뛚렷해졌다고 합니다.
- 사이버보안 자동 차단: 고위험 사이버 요청을 모델 단에서 자동으로 막는다고 합니다. 취약점 연구는 별도의 Cyber Verification Program 승인을 받아야 한다고 알려졌습니다.
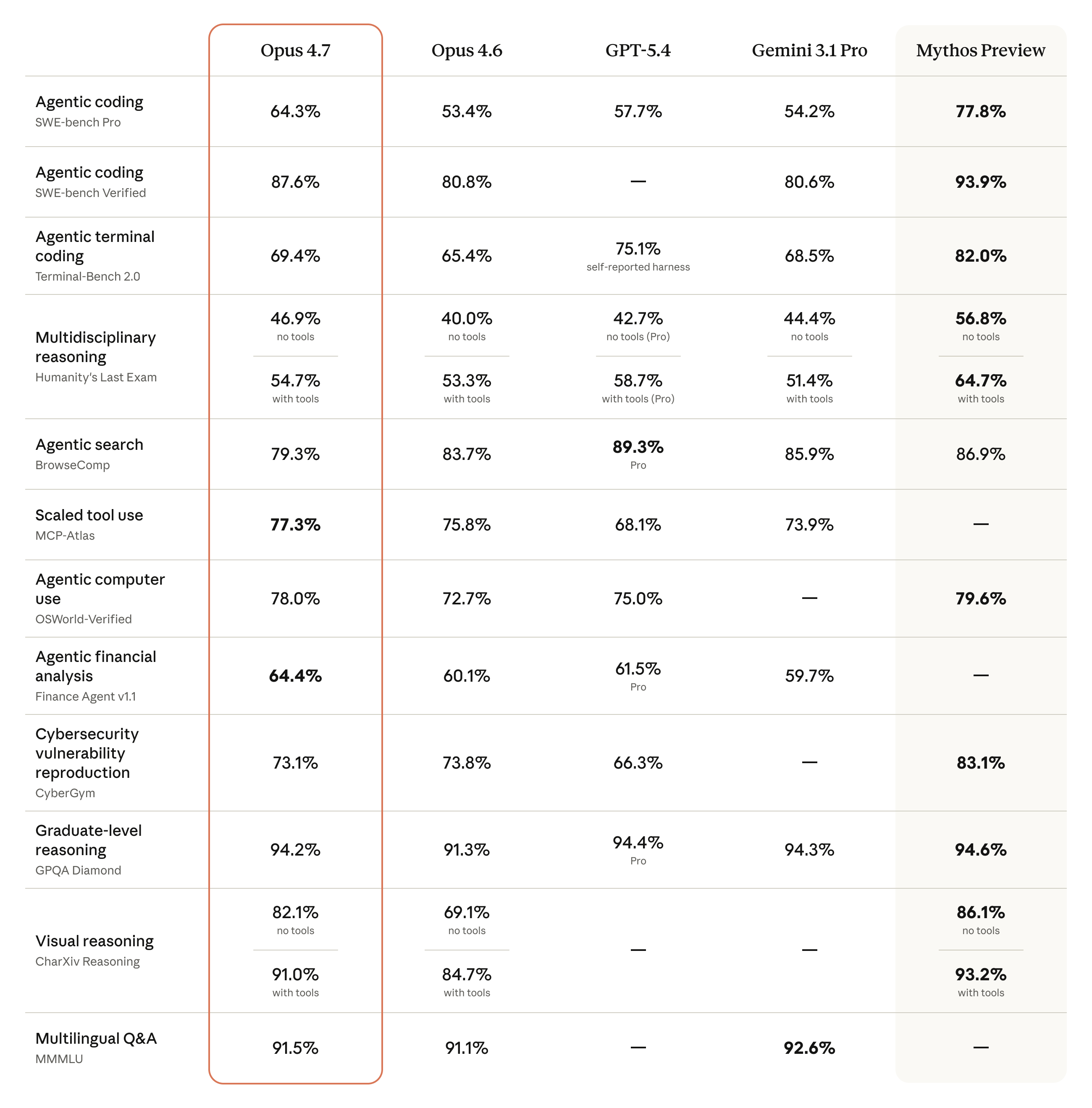
벤치마크는 분명히 올랐다고 합니다
Anthropic이 공개한 수치에 따르면, SWE-bench Verified가 80%대 초반에서 80%대 후반으로 올라가면서 같은 평가에서 Gemini 3.1 Pro를 앞섬다고 합니다. SWE-bench Pro도 50%대 초반에서 60%대 중반까지 올라가며 GPT-5.4와 Gemini 3.1 Pro를 모두 넘어섬다는 발표가 있었습니다. CursorBench에서도 10%포인트가량 올랐다고 하고, 문서 추론을 보는 OfficeQA Pro는 50%대에서 80%대로 크게 뛰었다고 합니다.
특히 놀랐던 부분은 비전 쪽입니다. 한 파트너사가 컴퓨터비전 용도로 돌려본 시각 정확도가 50%대에서 90% 후반까지 올라갔다는 보고가 있었고, Rakuten은 자체 SWE 벤치에서 4.6 대비 프로덕션 태스크를 3배 더 해결했다고 발표했습니다. 법률 문서를 다루는 BigLaw Bench도 90% 초반을 기록했다고 합니다.
 보안 정책으로 확대가 제한됩니다
이미지 출처: Anthropic, "Introducing Claude Opus 4.7" (2026-04-16)
보안 정책으로 확대가 제한됩니다
이미지 출처: Anthropic, "Introducing Claude Opus 4.7" (2026-04-16)
신규 기능들은 서로 물려 돌아가도록 설계됐다고 합니다. 입력이 들어오면 xhigh가 깊게 추론하고, Task Budget이 그 깊이를 남은 예산으로 제어하고, 자체 검증이 결과를 한 번 더 훑는 흐름입니다.
그런데 "같은 가격"은 아니라고 합니다
공식 가격표는 4.6과 똑같습니다. 입력 $5, 출력 $25. 그런데 실제 청구서는 올라간다는 보고가 꽤 올라와 있습니다. 이번 버전에 새 토크나이저가 적용됐기 때문이라고 합니다. Anthropic 마이그레이션 가이드에서도 동일 프롬프트가 1.0에서 1.35배 사이로 더 많은 토큰을 소비한다고 설명한다고 합니다.
출력 토큰이 입력의 5배라는 구조까지 겹치면, 체감 비용은 단순 1.2배 이상으로 뛰다는 이야기가 나옵니다. Decrypt가 직접 돌려본 게임 제작 테스트에서는 한 세션에서 토큰 할당량을 전부 소진한 사례까지 보고됐다고 합니다. xhigh가 기본값이 된 점까지 생각하면, 이 부분은 미리 염두에 두고 쓰는 편이 좋아 보입니다.
반대로 아쉬웠다는 영역도 있습니다
올라간 지표만 있었던 건 아니라고 합니다. 장문 맥락을 보는 MRCR 지표에서는 4.6보다 오히려 크게 떨어졌다는 보고가 있었고, 터미널에서 도구를 쓰는 Terminal-Bench와 에이전트 검색 쪽 BrowseComp에서는 GPT-5.4에 밀렸다고 합니다. 실제로 GitHub과 X에서는 "4.6이 내 워크로드에서는 더 잘 됐다"는 반응이나 "사실상 rebadged 4.6 아니냐"는 회의적인 목소리도 꽤 올라와 있습니다.
공식 벤치 14개 중 12개에서 앞섬다는 Anthropic 발표와 현장 체감 사이에 간극이 있다는 이야기이고, 이 부분은 각자 워크로드로 한 번 돌려봐야 확실해질 것 같습니다.
Claude Code 쪽 변화가 제일 손에 잡혔습니다
이번 업데이트에서 가장 체감이 크다고 느꼈던 건 Claude Code 쪽입니다. xhigh가 전 플랜에서 기본값이 되면서 결과물이 전보다 단단해진 느낌이 있었고, 새로 도입된 /ultrareview 명령어는 코드 리뷰 전용 세션으로 돌아가면서 버그를 심각도별로 정리해 돌려준다고 합니다. Pro와 Max 구독자에게는 월 3회가 무료로 제공된다는 안내도 있었습니다.
Max 플랜에서는 자동 모드가 확대됐고, 파일시스템 기반 장기 메모리 덕분에 세션이 바뀌어도 이전 맥락을 이어받을 수 있다고 합니다. OfficeQA Pro 오류가 줄어든 배경에도 이 장기 메모리가 있다는 설명이었습니다.
시온랩은 Opus를 주로 쓵니다. 그래서 매번 이렇게 점검합니다
시온랩은 클라이언트 프로젝트에서 주로 Opus 계열을 쓵니다. 클라이언트 시안부터 프로덕션 코드까지 비중이 크다 보니, Anthropic에서 새 모델이 올라올 때마다 기존에 구축해둔 워크플로우를 처음부터 다시 한번 점검하고 있습니다. CLAUDE.md 규칙, xhigh를 어디에 기본으로 둘지, /ultrareview를 코드 리뷰 루틴의 어느 지점에 끼울지, 토크나이저가 바뀌 만큼 긴 문서 작업을 같은 모델로 계속 밀지 아니면 4.6을 병행할지까지, 항목 하나씩 다시 시험해봅니다.
이번 4.7도 동일한 흐름으로 지켜보는 중입니다. 코딩 쪽은 확실히 손에 잡히는 개선이 있었고, 장문 맥락과 토큰 비용은 조금 더 검증이 필요한 영역이라고 보고 있습니다. 결론은 며칠 더 써본 뒤에 정리해야 할 것 같습니다.
버전 숫자는 빠르게 오르지만, 값을 내는 건 여전히 프롬프트 설계와 워크플로우입니다.
모델이 바뀔 때마다 기존 워크플로우를 다시 점검하는 이유도 여기에 있습니다.